Setting up Triggers
-
Print
-
DarkLight
-
PDF
Setting up Triggers
-
Print
-
DarkLight
-
PDF
Article Summary
Share feedback
Thanks for sharing your feedback!
You can use ControlUp triggers to record incidents and automatically perform follow-up actions when a predefined event occurs in your environment, or at a scheduled time. This article covers what you need to know to create triggers in your environment.
You can set up triggers to do things like:
- Notify you through email, mobile push notification, or a third-party service when a problem is detected in your environment.
- Save information in your ControlUp environment when a problem is detected for later analysis.
- Run a script action to automatically remediate a problem when it is detected.
Use Case
To learn how to use triggers to reduce IT ticket submissions, use our interactive use cases guide.
What Causes a Trigger to Activate?
You can create different types of triggers depending on when you want the trigger to activate. See the table below for the details of each trigger type.
For each type of trigger, you can specify additional conditions that must be met for the trigger to activate, and a schedule that defines when the trigger can activate. You can limit how often a trigger can activate by specifying a minimum duration between activations.
Trigger Types
| Trigger Type | Description |
|---|---|
| Stress Level | The Stress Level trigger activates by an increase in a record’s Stress Level value. This type of incident applies to all record types in ControlUp (Folders, Hosts, Machines, Sessions, Processes, Executables, and Accounts). Use this trigger to capture all types of performance issues, such as excessive resource consumption. |
| Windows Event | The Windows Event trigger activates when an entry in an operating system event log of your managed Windows computers is recorded. Use this trigger to record Windows event log entries for further analysis or troubleshooting. |
| Machine Down | The Machine Down trigger activates when a machine monitored by ControlUp becomes unavailable. (Note: Machine Down incidents are recorded by the ControlUp Monitor because continuous monitoring is required to detect a Machine Down event and the ControlUp Real-Time Console is not intended for continuous monitoring.) |
| Process Started | The Process Started trigger activates when a process matching a defined set of criteria is started on a managed machine. |
| Process Ended | The Process Ended trigger activates when a process matching a defined set of criteria is terminated on a managed machine. |
| User Logged On | The User Logged On trigger activates when a user logs on to a managed machine. |
| User Logged Off | The User Logged Off trigger activates when a user logs off from a managed machine. |
| Session State Changed | The Session State Changed trigger activates when the state of a user session changes on a managed machine. |
| Advanced | The Advanced trigger activates when a custom set of conditions applies to a row in ControlUp's information grid. Use this trigger type for situations that are not covered by any other trigger type. |
| Scheduled | The Scheduled trigger activates according to a custom schedule that you set. You can schedule the trigger to activate at a time of your choice either once, or on a regular schedule of minutes, days, weeks, or months. To learn how to schedule a trigger, watch our video. |
What Happens when a Trigger Activates?
When a trigger activates, it performs the follow-up actions that are configured for that particular trigger. See the table below for the details of each type of follow-up action.
A trigger also records an incident when it activates. You can view and analyze the recorded incidents in the Incidents Pane in the Real-Time Console to keep track of important events that have occurred in your environment. Scheduled triggers do not record an incident when they activate.
Note
An incident can be recorded only once every 5 minutes for a particular trigger.
Follow-up Action Types
| Follow-up Action Type | Description |
|---|---|
| Send an e-mail alert | Sends an email with the incident details to the selected recipients. A valid recipient is a ControlUp user in your organization who has verified their e-mail address by activating their ControlUp account. This follow-up action uses our backend services for delivering alerts and does not require a local mail server. |
| Dump view/s to disk | Creates a comma-delimited file with the content of the selected ControlUp views. |
| Record an event in the Application Log | Creates a new log entry in the Windows Application Log of the computer which detected the incident. |
| Play a sound alert in the console | When the trigger is activated, a selected sound file will be played if the ControlUp Real-Time Console is open. |
| Send an e-mail alert using a local SMTP server | Sends an email alert with incident details to any number of valid e-mail addresses via a user-configured SMTP server. Your organization will only be able to send messages using the SMTP server if you have an active instance of a ControlUp Monitor configured with the necessary credentials and connection details. For details on on how to configure SMTP Monitor settings, see SMTP Settings. |
| Run an action | Runs a Script Action when the trigger activates. For details on how to configure automated actions, see Automated Actions - User Guide. |
| Send a RESTful API request | Sends a notification to an external system using a webhook when the trigger activates. For details on how to configure webhooks, see Using Webhooks as Follow-Up Action. |
Manage your Triggers
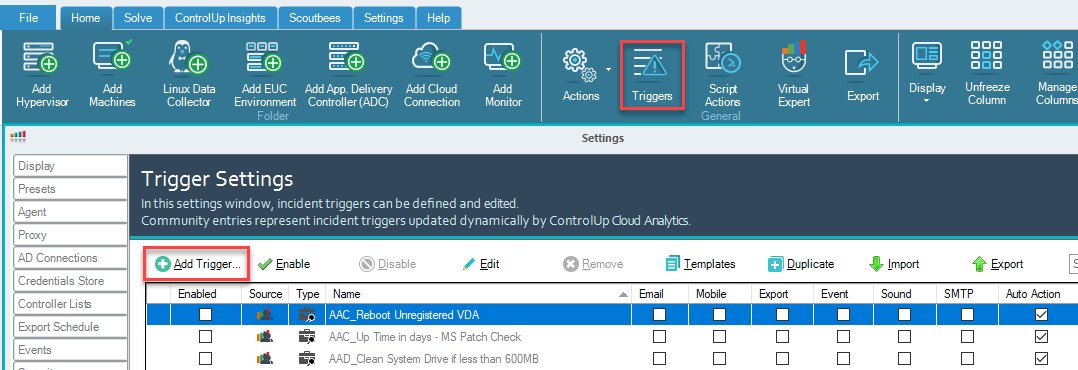
To access the trigger settings window, click on Triggers in the Home ribbon of the Real-Time Console.
In the trigger settings window, you can see built-in triggers that are configured for common use cases, and user-defined triggers that have been added to your ControlUp organization. You can enable or disable triggers, edit triggers, create new triggers, and export/import triggers.
Export and Import Triggers
You can export one or more selected triggers to a JSON file by clicking Export in the trigger settings window. This lets you back up triggers and import them on a different system.
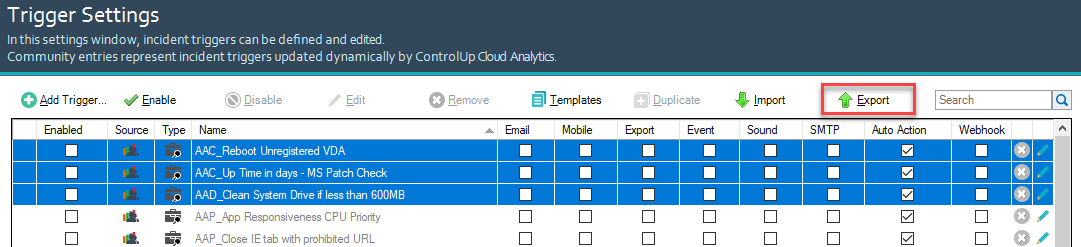
To import triggers, click Import and select a JSON file that contains one or more exported triggers.
Importing from a different ControlUp organization
If you export a trigger from one organization and import it to another, all organization-specific information is erased. The scope of the imported trigger defaults to the root of your organization including all subfolders. Follow-up actions are also erased. Edit the trigger after you import it to set the scope and follow-up actions for the new organization.
Prerequisites
Make sure you have the following requirements before you set up triggers:
- Your ControlUp user has permission to Configure Incident Triggers. Permissions are configured in the Security Policy Pane.
- You have a ControlUp Monitor running in your organization. The Monitor activates the trigger when the appropriate conditions are met.
Create a Trigger
To create a new trigger, perform the following steps:
- In the Home ribbon of the Real-Time Console, go to Triggers > Add Trigger to open the Add New Trigger window.
- Select the type of trigger that you want to add and click Next. For details about each type of trigger, see the Trigger Types table above.
- Depending on the trigger type selected, you might have to set trigger parameters. If your trigger type is not listed below, then you can skip this step.Stress Level
Record Type Set the record type that can cause the stress level trigger to activate (Folder, Machine, Session, Process, etc.). The record type that you select determines the metrics you can use when applying filter criteria conditions to the trigger. Stress Level Set the minimum threshold for the stress level at which the trigger activates. Duration Set the minimum duration that the stress level condition must be met for the trigger to activate. Duration Set the minimum duration that the stress level condition must be met for the trigger to activate. Machine DownRecord an incident Set the situations that activate the trigger. Minimum duration Set how long a machine must be down for the trigger to activate. Session State ChangedFrom State Set the required initial state of the session. To State Set the required subsequent state of the session. Minimum duration in new state Set how long the session has to be in the state set with To State to activate the trigger. AdvancedRecord Type Set the record type that can cause the trigger to activate (Folder, Machine, Session, Process, etc.). The record type that you select determines the metrics you can use when applying filter criteria conditions to the trigger. From this state Optionally, use the filter editor to configure an initial state for the record. To include machines that were just discovered, and therefore have no initial state, select the Include machines that were just discovered checkbox. To this state Use the filter editor to configure a state for the record which will cause the trigger to activate when the record reaches that state. Minimum duration in new state Set the minimum time period that the record must be in the new state for the trigger to activate. Using the filter editorFor details on how to use the filter editor to define the initial and subsequent states for the trigger, see Add Conditions to the Trigger below.ScheduledScheduled triggers and Monitor time zonesThe time that you set for a scheduled trigger is in the time zone of the ControlUp Monitor that activates the trigger. It is not based on the time zone of the monitored records. If you create a scheduled trigger that is activated from multiple Monitors in different time zones, then the triggers do not activate simultaneously.- Select the Record Type to which the trigger applies. Selecting a record type allows you to apply conditions that must be met on that record type for the trigger to activate.
- Select how often you want the trigger to run with the Schedule dropdown. You must enter additional parameters to define the schedule.
Schedule option Description Daily The trigger activates on a daily schedule.
The trigger first activates at the Start date and time that you set. The trigger then activates at the same time on subsequent days. If you don't want the trigger to activate every day, then you can set an interval of days with the Occur every parameter.One Time The trigger activates only once.
The trigger activates at the Start date and time that you set. This is the only time that the trigger activates.Per Minute The trigger activates on a set interval of minutes.
The trigger first activates at the Start date and time that you set. The trigger then activates every number of minutes that you set with the Recur every parameter. Set the End date and time of when you want the trigger to stop activating.Weekly The trigger activates on a weekly schedule.
The schedule begins at the Start date and time that you set. The trigger activates at the time of day entered in the Start field on the specified days of the week. If you don't want the trigger to activate on these days every week in a row, then you can set an interval of weeks with the Occur every parameter.Monthly The trigger activates on a monthly schedule.
The schedule begins at the Start date and time that you set. The trigger activates at the time of day entered in the Start field, on the days that you specify.- Enter the Months that you want the trigger to activate, in a comma-separated list. You can enter:
- Numbers representing months. For example, "1,2,6,12".
- Names of months. For example, "January,February,June,December".
- "All" if you want the trigger to activate during all months.
- Select the days of the month that you want the trigger to activate in comma-separated lists. There are two ways to do this:
- Select Days if you want to enter dates in the month. You can enter dates ranging from 1-31, and you can enter "Last" if you want to activate the trigger on the last day of the month.
- Select On weeks if you want to enter days of specific weeks in the month.
- Enter the weeks of the month. The available values are: 1, 2, 3, 4, First, Second, Third, Fourth, Last.
- Enter the days of the week. The available values are: 1, 2, 3, 4, 5, 6, 7, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, All.
- Enter the Months that you want the trigger to activate, in a comma-separated list. You can enter:
- On the next page, if you want to add additional conditions that must be met for the trigger to activate, then you can add them by clicking Filter editor. The trigger will not activate if these conditions are not met. For details, see Add Conditions to the Trigger below.
- Click Next.
- Set the Scope for the trigger by selecting items in your ControlUp organization file structure. Only items (machines, sessions, processes, etc.) in the selected folders can cause the trigger to activate. Use the scope to limit the areas of your organization that activate the trigger.
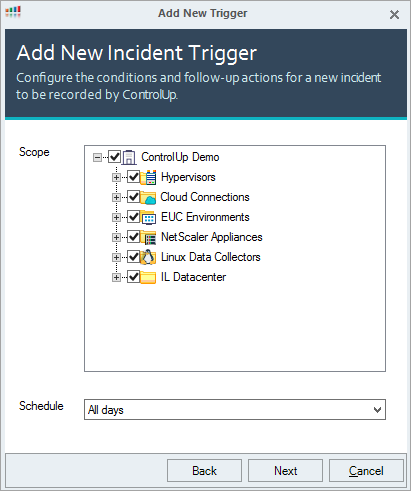
- If you want to define periods of time when the trigger can activate, click the Schedule dropdown and select a schedule. Outside of the defined period, the trigger can't activate, even under situations that would normally activate the trigger. By default, the trigger can activate on all days.
You can select a previously created schedule from the dropdown, or select Add New Schedule to create a custom schedule. For details on how to customize a schedule, see Schedule Settings.Set the schedule in the Monitor's time zoneThe schedule that you select is in the time zone of the ControlUp Monitor that activates the trigger. It is not based on the time zone of the monitored records. - After you have selected a scope and a schedule, click Next.
- Define the follow-up actions that you want to perform when the trigger activates. You can add multiple follow-up actions.
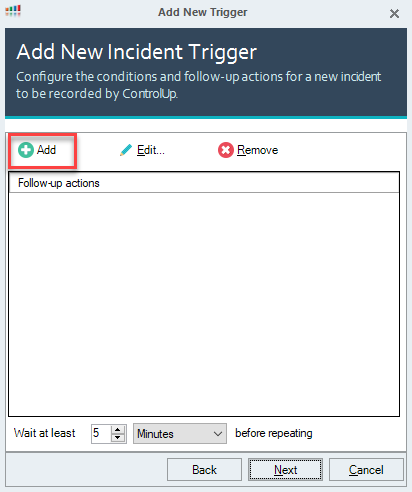
- Click Add to open the Follow-up Action window.
- Select a Follow-up Action from the dropdown. For details about each type, see the Follow-up Action Types table above.
- Configure the additional options for your action type that you selected.
- Click OK in the Follow-up Action dialog box.
- For some trigger types, you can enter a minimum duration between trigger activations with Wait at least . . . before repeating. For example, you might want to increase the duration so that the follow-up actions are not performed too often.
- Click Next.A follow-up action is not requiredTriggers record incidents in the Incidents Pane in the Console even if no follow-up action is configured. Note that scheduled triggers do not record incidents when the trigger activates.
- On the next page, give the trigger a name and a description. You should make sure that the automatically generated name and description accurately describe what you intended the trigger to do.
- Click Finish.
Add Conditions to the Trigger
While creating a trigger, you can add conditions (filter criteria) that must be met for the trigger to activate. The conditions are evaluated against the selected records for your trigger.
For example, you can configure a Stress Level trigger that is activated only by processes with a certain name, or a Windows Event trigger that is activated only by specific event IDs. In these cases, the process name and event ID can be added as the trigger conditions.
Note
The Filter Editor dialog box is similar to the Item Level Targeting filter control used in Microsoft Windows Group Policy Management Console (GPMC) and uses the same logic.
To add conditions:
- Click Filter editor… when creating a trigger to open the filter editor.
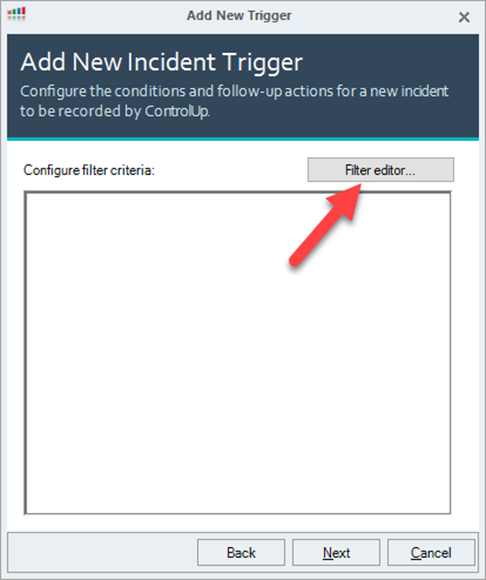
- Click New Item and select an attribute, rule, and value to add a condition. You can add multiple conditions. Note that when configuring search criteria on a string attribute, you can include wildcards using the * (asterisk) symbol.
- If you have added multiple conditions, set the AND/OR logic of the conditions by clicking Item Options.Use collections when combining AND and OR statementsIf you are using both AND and OR statements in your filter criteria, then you should group your conditions into collections. See the section below on how to use collections.
You don't need to use collections if you are using only AND conditions or using only OR conditions. - By default, conditions are simple match. You can include wildcards using the * (asterisk) symbol in simple match conditions. If you want to use regular expressions (RegEx) for conditions, select the Use Regular Expression option and enter a RegEx pattern in the condition field.
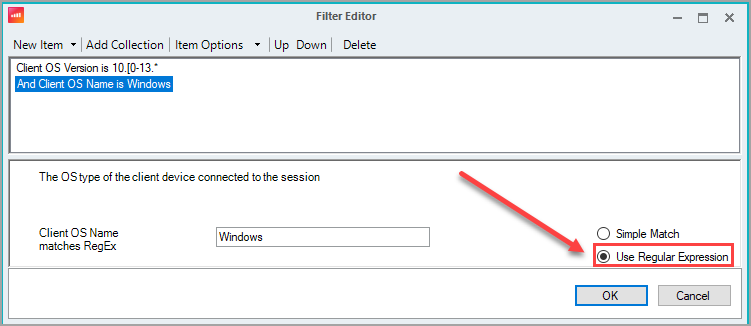
- After you have added your conditions, click OK to return to the trigger creation window.
Combine conditions into AND/OR groups
If you need to combine AND and OR conditions in your filter criteria, then you can group filter conditions into collections. You can apply AND or OR rules to each collection, as well as to each condition within the collection.
To add a collection of conditions:
- In the Filter Editor, click Add Collection to add your first collection.
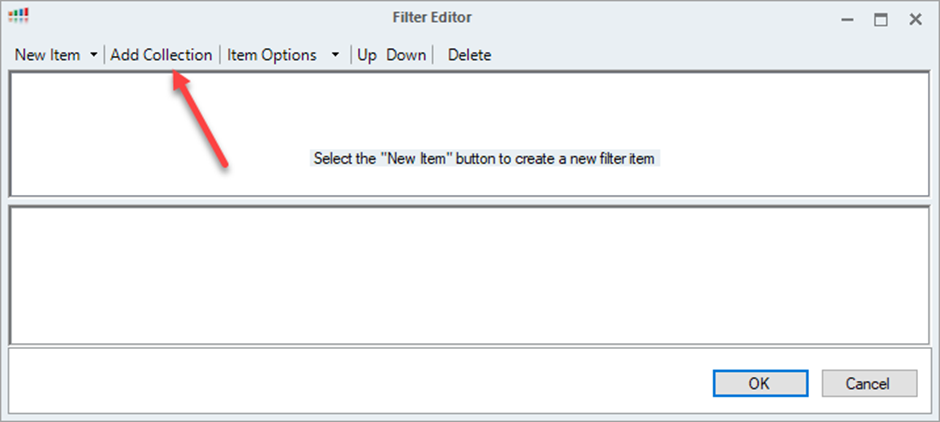
The new collection is set to True by default. You can switch between True and False by clicking Item Options when the collection is selected.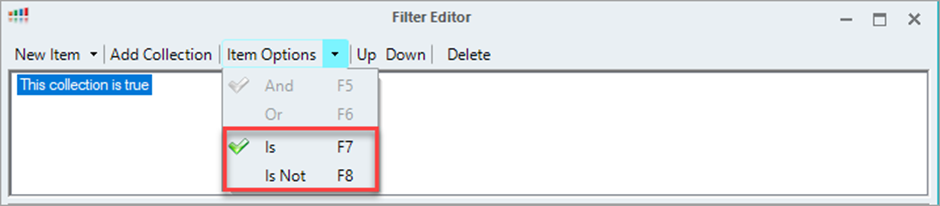
- To add conditions to the selected collection, click New Item and select the metric you want to use to define the condition.
- Add another collection. You can move the collection to the same level as the first collection by clicking Down with the collection selected.
- Set an AND/OR rule for the second collection by clicking Item Options with the collection selected.
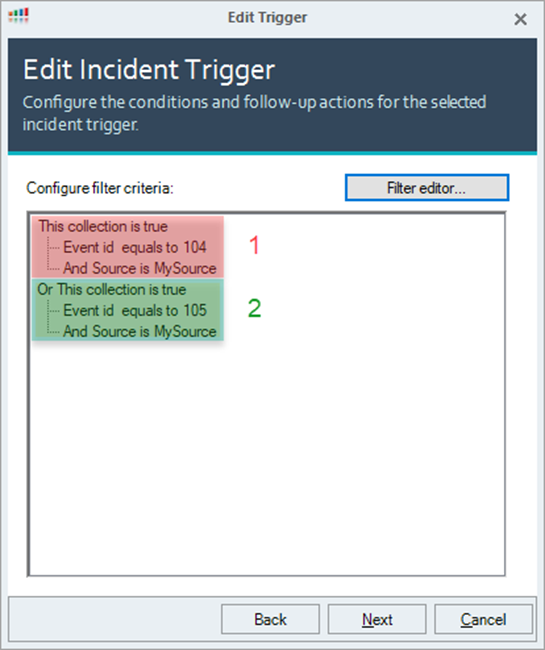
Collections Example
In this example, we use a Windows Event Trigger that we configure with two Collections. The first collection is configured with EventID 104 and source “MySource”. The second Collection is configured with EventID 105 and the same source starting with the OR operator.
The OR operator indicates that the trigger is fired if one of the two Collections returns TRUE. Programmatically, this can be viewed as follow:
(EventID = 104 AND Source = “MySource”)
OR
Was this article helpful?