ControlUp Monitor Clusters
- Print
- DarkLight
- PDF
ControlUp Monitor Clusters
- Print
- DarkLight
- PDF
Article Summary
Share feedback
Thanks for sharing your feedback!
Users can monitor large organizations with thousands of data sources effectively with ControlUp. The Monitor Cluster feature enables multiple ControlUp Monitors to work together to monitor a single organization.
Each monitor can handle up to 2,500 VMs with 160 processes per machine, or up to 320,000 total processes per monitor node.
While a single monitor can handle up to 2,500 data sources (e.g. VMs), a cluster of monitors can handle over 50,000 data sources.
Note
A data source is any logical resource in your organization monitored by ControlUp, including physical and virtual machines, hypervisors, XenDesktops, NetScalers, etc.
The following article explains the ControlUp Hybrid Cloud solution. The functions of the monitors are also valid for the ControlUp On-premises (COP) solution, where the COP Server performs the same functions as the cloud in the Hybrid Cloud solution.
The diagram below shows how a large organization with 32,000 data sources in two sites uses multiple ControlUp Monitors to monitor the entire organization:
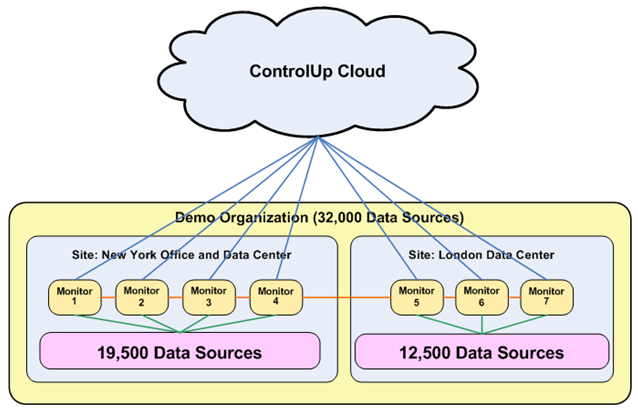
Deploying Multiple Monitors in an Organization
In ControlUp deployments where less than the maximum-supported capacity (320,000 total processes) per monitor node, a single ControlUp Monitor can usually perform all of the tasks listed above. For larger organizations, multiple monitors are required. For more details, see Sizing Guidelines for ControlUp v8.x.
Note
The exact number of data sources that can be monitored by a single ControlUp Monitor varies from organization to organization, depending on the specific configuration of hardware and software.
If you add multiple monitors to your organization, they are automatically deployed as a cluster. Each monitor in the cluster is assigned particular roles. Typically, each monitor is responsible for collecting data from specific data sources and performing a preliminary aggregation of the data it collects.
In addition, a monitor might be tasked with completing the aggregation process for all the data retrieved by all of the monitors in the cluster, preparing and sending the data to the web UI, and/or other functions.
How Monitor Clusters Are Managed
In a monitor cluster, one monitor acts as the Master Monitor. This monitor is responsible for dividing all of the organization’s monitoring tasks among the monitors in the cluster. All the other monitors in the cluster are subordinate to the Master Monitor.
The Master Monitor decides on-the-fly which monitors will perform each monitoring task in the organization. It can change the assignments as necessary based on the load each monitor handles at a given time.
The first monitor you deploy in your organization performs a check-in to our cloud backend and is then automatically chosen as the Master Monitor. The role of the Master Monitor can move between monitors in any site.
Linking Monitors to Sites
Removed AD Dependency
From version 9.0, you can deploy ControlUp Monitors on machines that are not joined to a local Active Directory (AD) domain. For details, see Removed AD Dependency for Monitors.
To enable the linking of monitors to the data sources at their location, ControlUp supports the creation of sites. Each distinct physical location in your organization (e.g. your New York data center and London data center) should have its own site.
You should configure each site to include all the monitors, and all the data sources they monitor, that reside in that site. The Master Monitor only tasks monitors in each site with the job of collecting data from the data sources in that site.
Note
You can only deploy one monitor cluster in a single organization, even if the organization has multiple sites. A site can have multiple monitors.
Planning the Organization Monitor Configuration
We recommend that you should set up separate monitors at each physical site where a significant number of data sources are located. For example, if your organization has two data centers in Washington and Paris, with about 3,000 data sources each, it is best to set up a monitor in N+1 configuration for High Availability (HA) at each site.
The diagram below shows an example configuration of monitors for a large organization.
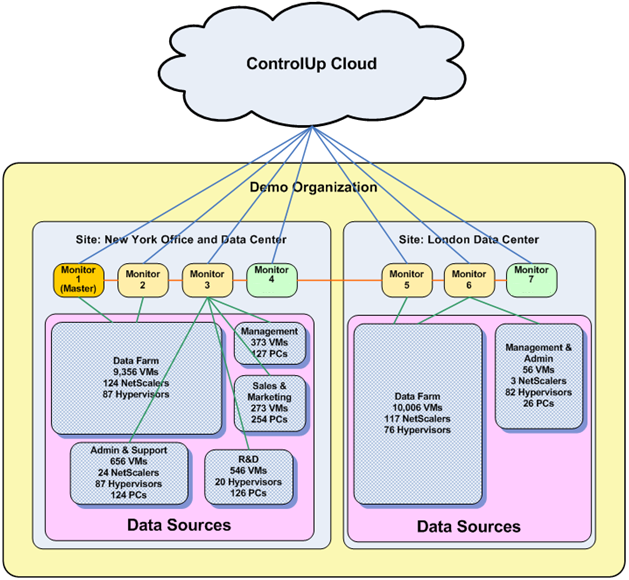
For information about the system requirements of monitors, see Sizing Guidelines for ControlUp v8.x
Allowing for Backup and High Availability
If you deploy a single monitor in your organization, HA is implemented by setting up two monitors to operate as an active/passive HA pair. If the primary monitor fails, the secondary monitor automatically takes over its functioning, ensuring that the monitoring process isn't interrupted.
If you deploy a monitor cluster in your organization, you can implement HA by setting up one more monitor at each site than required, given the number of monitored data sources. When all monitors at a site function properly, some of their available resources remain idle. If any monitor at a site fails, the Master Monitor divides up the failed monitor’s tasks among the other monitors running at the site.
In addition, one monitor in each cluster is designated to be the Master Monitor’s backup. This is an internal role that the Master Monitor dynamically assigns to a different monitor.
When the Master Monitor runs, the backup stores an up-to-date replica of the Master’s state. If the Master fails, the backup automatically takes over for it.
Associating Related Data Sources
Logical entities in an organization are often related to one another. For example, a monitored hypervisor and all the guest OS data of the VMs running on it are separate logical entities, but they are also related to one another. The data presented in the ControlUp Console wouldn't be complete if it ignored the relationships between logical entities.
To enable ControlUp to match data from related data sources, the properties of every monitored data source include an association index. Related logical entities, like hypervisors and their VMs, all have the same association index.
Association indexes enable ControlUp to match data from related data sources even if they are tracked by different monitors. At each site, one monitor is responsible for matching the data from different sources based on their association indexes. This monitor retrieves all the current activity data for each association index from the other monitors at the site and merges the information to produce a complete picture of each entity’s status.
Merging of data by association index is only performed per site, and not for the entire organization. Due to this, we don’t recommend you assign related data sources to different sites. For example, if a hypervisor and its VMs are assigned to different sites, it isn't possible to drill down from the hypervisor to its VMs.
Was this article helpful?